Azure コンテナーアプリの可視化戦略(前編)
Observabilityとは何か
私たちのシステムは一定の条件下ではブラックボックスのようになります。リクエストを投げ込んで何かを取り出す、しかし内部では何が起こっているのでしょうか?Observabilityは、外から見たときにシステムをどれだけ理解できるかを測るものです。
それはモニタリングとは違うのでしょうか?
モニタリングは何かが間違っているときにそれを教えてくれます。例えば、CPUが過負荷になっているか、何かの不具合が物事を遅くしているかなどです(それが 「何」 です)。
一方、Observabilityは探偵のようなものです。それは問題の背後にあるストーリー(「なぜ」)を理解するのに役立ちます。例えば、アプリが遅く応答しているとします。私たちは問題を示すたくさんのクールなチャートやグラフを持っているかもしれませんが、それらはなぜそれが起こっているのかを教えてくれるでしょうか?必ずしもそうではありません。それが、しっかりとしたObservabilityが必要です。それは私たちのシステムへの視界をより良くし、それによって問題をより早く解決します。そして、問題を早く解決すると、顧客はよりスムーズで信頼性の高い体験を得ることができ、より幸せになります。
何を測定するか
システムの内部で何が起こっているのかをしっかりと把握するために、本当に測定する必要があるものを見てみましょう。
Observabilityを私たちがシステムを外から理解する方法と考えてみてください。それを実現するためには、データが必要ですよね?では、どのようなデータを収集すべきでしょうか?
主に3つのことがあり、これらはしばしばObservabilityの柱と呼ばれます:
- Metrics:これらは、残りのメモリがどれだけあるか、CPUがどれだけ働いているかなど、特定のことを教えてくれる数字です。これはあなたの車の速度計や燃料計をチェックするようなものです。
- Logs:シンプルなプログラムを書いて、何が起こっているかを見るためにprint文を使ったことはありますか?それがログです。これは、言葉でのイベントの記録です。今日でも(私自身がそうですが)、コードにprint文を追加してデバッグを行っています。
- Traces:トレースとは、システムを通じてリクエストのルートを追跡することです。リクエストがシステムを移動すると、各ステップでログとメトリクスを生成します(覚えておいてください、これらを収集したいのです)。トレースの重要な部分は、各リクエストにはTrace IDがあるということです。これは、始まりから終わりまでそれと一緒にいるタグです。このTrace IDは重要です。なぜなら、それはすべてのデータ―すべてのログとメトリクス―をその特定のリクエストに関連付けるからです。リクエストが他のアクションを引き起こしたり、より多くのプロセスを呼び出したりすると、これらの子プロセスは自分自身のIDを得ます。これをParent IDと呼びます。Parent IDは、それがどこから来たのかを思い出させるもので、それを初期のリクエストにリンクします。Trace IDは、全体の旅をチェックし続けるための接着剤であり、Parent IDは家系図を描き出し、各サブプロセスが大きな操作の一部であることを示します。この設定により、リクエストがドアをノックするときからシステムを離れるときまでの全体の旅を追うことができます。
Observability戦略
堅牢なObservability戦略には、いくつかの重要な要素が含まれます:
- Instrumentation:Instrumentationは、コードでテレメトリ(メトリクス、ログ、トレース)をキャプチャするプロセスであり、最も大きな投資を必要とする部分と言えます。自動的にそれを行う多くのSDK(ライブラリ)やコードレス(エージェントベース)のツールがあります(後述)。
- Export:アプリケーション自体やオペレーティングシステムからこのテレメトリデータをすべて収集し、特定の場所に送信する能力が必要です。
- Centralized Repository:ログ、メトリクスを保存し、トレースを考慮に入れてこれらすべてをリンクするリポジトリが必要です。
- Visualize and Query:これは、集中化されたリポジトリにあるデータを見て理解するためのツールを持つことについてです。それを検索し、理解しやすい形で見ることができるべきです。
- Take Action:これは戦略の積極的な部分です。データが特定の限界に達しているか、それを超えていることを示しているとき、システムは自動的に自分自身を調整するべきです(例えば、CPUが過労であればリソースを増やすなど)または、エンジニアにピンを送って見て、何をすべきかを決定します。
良いObservability戦略における一つの重要な要件:システムのすべての部分が測定されるべきです。それは言うほど簡単ではありませんが、それを助けるツールがあります。
Azure Monitorの概要
Azure Monitorについて深く掘り下げると、このブログが長くなりすぎるので、概要だけを提供します。
Azure Monitorは、AzureネイティブのObservabilityツールで、さまざまなリソース(アプリケーション、Azureリソース、Activity logsなど)からメトリクスとログを収集し、それらをAzure Log Analyticsのような集中化されたリポジトリに保存し、アラートを設定する機能を提供します。
Azure Monitorが提供するInstrumentationライブラリを使用して、アプリケーションからトレースを収集することもできます。
Azure Container Apps Observabilityの概要
要約すると、私たちはメトリクス、ログ、トレースを収集し、システムのすべての部分を測定するという要件を満たす必要があります。ありがたいことに、Azure Container Appsは、その要件を満たすのを容易にしてくれます。
Azure Container Appsを使用すると、以下のものを収集することができます:
- アプリケーションレベルのログ、メトリクス、トレース:Open Telemetry SDKを使用したアプリケーションレベルのログ。リクエスト/レスポンス時間、例外などを収集し、集中化されたリポジトリ(Azure Log Analytics)に送信することができます。
- コンテナレベルのログ:コンテナはログ(アプリケーションの外部)を生成します。これをstout & sterrと呼びます。
- システムログ:Container Appsリソース自体が、”service level”のイベントを通知するためのログを生成します。ボリュームマウント、トラフィックスプリットなど、リソースレベルで行うことすべてです。
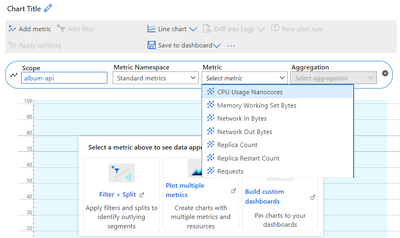
- リソースメトリクス:すべてのAzureリソースは自動的にメトリクスを発生させます。これを標準メトリクスと呼びます。Azure Container Appsでは、これにはCPU使用率、リクエスト、ネットワークイン(バイト単位で測定)などが含まれます。これらのメトリクスを表示するためには、Metrics explorerを使用できます。
注:コンテナレベルのログとシステムログは自動的に収集・ストリーミングされます(ほぼリアルタイムで表示可能)、Azure Log Analyticsにルーティングすることを選択できます(クエリの目的のため)、またはDiagnostic Settingsを利用してログをAzure Storage AccountやEvent Hubに送信することもできます(その後、サードパーティのアプリケーションによって消費されます)。
OpenTelemetryとAzure Application Insightsを使用したInstrumentation(アプリケーションレベル)
OpenTelemetryは、クラウドネイティブのシーンでInstrumentationの選択肢として目立っています。これは、ログ、メトリクス、トレースをどのように収集し、扱うかを標準化することを目指した、コミュニティによるオープンソースプロジェクトです。
OpenTelemetryが目立つのは、ベンダー非依存の性質であり、特定のプラットフォームに縛られることなく、テレメトリデータを収集し、任意の目的地に送信できることを意味します。例えば、私たちが議論しているシナリオでは、データはAzure Monitor(Azure Application Insights)に送信されることも、他のどこかに送信されることもあります。