プロンプト エンジニアリングの実践
プロンプト エンジニアリング
言語モデルを使用するには、ユーザーはモデルに対し、人間と会話するように自然言語で命令を行います。この命令を含んだメッセージを プロンプト と言います。
自然言語で対話可能な AI モデルはこれまでにもありましたが、LLM が従来のものと異なる点として、命令された自然言語を認識するのに個別のトレーニングを必要とせず、即時に理解し、適切な応答を生成することができる点が挙げられます。
たとえば、以下のプロンプトでは文章の中から指示された “場所” と “時間” と “天気” といったエンティティを抜き出すことができます。
以下の文章の中から "場所" と "時間" と "天気" の情報を抜き出してください :
明日は AM 7:00 から高尾山に登山に向かいます。天気予報は晴れですが、念のために雨具の準備をお願いします。
従来の言語理解モデルで同様のことを行うには、事前に発話のサンプルを複数用意し、目的のエンティティに対しラベルを付けてトレーニングを行うといった処理が必要でした。
また単にテキストの応答の生成だけでなく、プロントによってモデルに対して特定のタスクを実行させることも可能です。
たとえば、以下のプロンプトでは、会話の応答はもちろん、ランダムな数字の生成、会話のカウント、素数の判断を行っています。
私たちは交互にランダムな数字を答えていきます
お互いの回答数が 5 回を超えたら会話を終了し、あなたはお互いの会話の中で出てきた素数を列挙してください
(※)このプロントを演習の環境で試すには 過去のメッセージを含む のパラメーターを 10 より大きく設定してください
つまり、プログラムを構成する処理の要素である入力、出力、演算、繰り返し、条件分岐などを自然言語で記述し、モデルに対して実行させることができます。
また、以下のような機能も提供します
-
要約
例
以下の文章を要約してください : (ここに要約したい文章を入力) -
抽出
例
以下の文章から○○についての情報を抜き出してください : (ここに抜き出したい情報をもつ文章を入力) -
翻訳
例
以下の文章を英語に翻訳してください : (ここに翻訳したい文章を入力) -
フォーマット変換
例
以下のマークダウンの表を HTML の table タグにしてください : | 項目 | 値 | | --- |--- | | **Subscription** | TrainingSub | | **Resource group** | AOAI Bot | | **Region** | japan east | -
コード生成
例
以下の説明をもとに JavaScript の関数を生成してください : 引数 url を受け取り HTTP Request を送信し、response された内容を返す callAPI という名前の関数つづけて以下のようにプロンプトを使用すると他の開発言語に変換することもできます。
例
回答にある関数を Python で記述してくださいまた以下のようにテキストで表せる様々なものを生成することもできます。
例
以下の絵文字を svg のタグで表現してください : 😃 -
画像認識
GPT-4 Turbo with Vision のようなマルチモーダルモデルを使用する場合は OCR によるテキストの抽出や画像の認識なども行うことができます。
プロンプト例
添付した画像の設定画面をもとに貼り付け可能なマークダウンの表のタグを生成してください (Azure の設定画面などの画面を貼り付ける)
上記のようにプロンプトを効果的に使用することで、生成するテキストの品質を上げるだけでなく、より複雑なタスクをモデルに実行、生成などを行うことができます。
プロンプト エンジニアリング は、モデルが生成するテキストの品質を向上させるための手法で、モデルに対して適切なプロンプトを提供することで、モデルが特定のタスクを効果的に実行し、望ましい出力を生成するように導くことができます。
プロンプトの構造
言語モデルに対するプロンプトを構成す要素はさまざまなドキュメントで説明されており、それぞれ微妙な差異がありますが、多くに共通して挙げられているものには以下のものがあります。
-
指示: モデルに対する具体的なタスクや指示
-
コンテキスト: モデルがより良い応答を生成できるように、外部情報や追加の文脈を提供
-
入力データ: 質問や解決したい問題を含むデータ
-
出力形式の指定: 期待する出力の形式やスタイルを明示
-
具体例: モデルに期待する出力の例を提供し、理解を補助
効果的なプロンプトを作成するためのヒント
言語モデルからより正確で適切な応答を得るための一般的なヒントとしては以下のものがあります:
- 明確な指示: モデルに対して明確な指示を提供し、タスクの目的を明確にする
- 指示の書式: 最新性バイアスがモデルに影響する可能性があり、プロンプトの末尾近くにある情報の方が、先頭にある情報よりも出力に与える影響が大きい可能性があるのでそれを考慮する
- セクション マーカーを使う: プロンプトの先頭に指示を配置し、### または “”” 、— を使用して指示とコンテキストを区切る
- 例を提供して目的の出力形式を明確にする: モデルに期待する出力の例を提供し、理解を補助する
- 抽象的で不正確な説明を減らす: モデルに対して可能な限り正確で具体的な情報を提供し、不正確な情報を生成する可能性を減らす
プロンプト エンジニアリングの代表的な手法を試す
プロンプト エンジニアリングの手法についてはさまざまなものが提唱されています。
その中でもこれまでの機械学習のコミュニティの論文等から提唱された代表的な手法について、実際に言語モデルとの対話を通じて動作を確認します。
具体的な手順は以下のとおりです。
[手順]
-
プロンプトを試す方法はいくつかあります。以下のツールからお好みのツールを選択し、プロンプトを入力して回答を確認します。
代表的なツール リンク Microsoft Copilot のチャット画面 Microsoft Copilot GitHub Models で試したい LLM Model を選択し、チャット プレイグラウンド画面 GitHub Models Azure AI Foundry にサインインし、自分でデプロイした言語モデルのチャット プレイグラウンド画面 Azure AI Foundry -
言語モデルとのチャット画面で各ステップのプロンプトを順に入力し、プロンプトと回答内容を確認します
-
Zero-shot prompting : この手法はモデルに対して特定のタスクを実行するための具体的な例を提供せずに、直接指示を与える手法です。これにより、モデルがそのタスクを初めて実行する際にどのように対応するかを評価できます。
プロンプトの例は以下の通りです:
以下の文章を日本語に翻訳してください : "Hello, how are you?"以下の文章が感情的に Positive なものか Negative なものか判定してください : 昨日は雨が降っていてがっかりしましたこの手法は言語モデルがあらかじめ持っている学習内容を元に自由な回答を生成させる手法であるため学習していない内容に対しては正確な回答が得られないことがあります。
-
Few-shot Learning : この手法はモデルに対して少数の具体例を提供することで、特定のタスクを実行する能力を向上させる手法です。プロンプトにいくつか実際の質問と回答例のペアを記載します。
プロンプトの例は以下の通りです:
動物の種別について対応するものを回答してください : 例1: "鮪" 答え1: "魚類" 例2: "牛" 答え2: "哺乳類" 質問: "トカゲ"明確な指示のない以下のシンプルなプロンプトにも回答が得られることを確認します:
犬 : ワン 猫 : ニャー 牛 : モー 羊 :1 つだけの例を提供する場合 One-Shot と呼ぶこともあります。
この手法は例を提示するものの、言語モデルがあらかじめ持っている学習内容を元に自由な回答を生成させる手法であるため言語モデルが学習していない内容に対しては正確な回答が得られないことがあります。
-
Chain-of-Thought(CoT) : この手法は複雑な問題を解決する際に、問題解決に至るまでの思考過程を自然言語で明示する手法です。具体的には中間的な回答を一度出力し、その回答を元にして最終的な回答を出力させるようにします。このように中間手順を踏むことで性能の向上が期待できます。
たとえば、以下のプロンプトの回答が正しく返らない場合(※):
12 個のリンゴを 3 人で均等に分けると、1 人あたり何個のリンゴを持つことになりますか?以下のように CoT プロンプトを使用して回答を求めることができます:
12 個のリンゴを 3 人で均等に分けると、1 人あたり何個のリンゴを持つことになりますか? ステップ 1: まず、12個のリンゴを3人で分けるために、12を3で割ります。 ステップ 2: 12 ÷ 3 = 4 ステップ 3: したがって、1人あたり4個のリンゴを持つことになります。 答え : 4 個 問題 : 18 個のリンゴを3人で均等に分けると、1 人あたり何個のリンゴを持つことになりますか?(※) GPT-4 モデルではこの程度の問題は正しい回答が返ります。しかし、予算の都合で GPT-3 などのモデルを使用する場合や、SLM (Small language model) を使用した際、回答の精度が低い場合には CoT を使用することで回答の精度を向上させることができます。
-
Zero-shot CoT Prompting : これはプロンプトに「ステップバイステップで考えてみましょう」という文言を追加することで回答の精度を上げるという手法です
たとえば、以下のプロンプトの回答が正しく返らない場合(※):
私は農家から10個のリンゴをもらいました。2 人の同級生に 1 ずつ、隣の家の兄と弟に 1つずつあげました。 それからまた5つのリンゴを貰って1つ食べました。 残りは何個ですか?以下のように「ステップバイステップで考えてみましょう」と文言を追加することで精度を高めることができます:
私は農家から10個のリンゴをもらいました。2 人の同級生に 1 ずつ、隣の家の兄と弟に 1つずつあげました。 それからまた5つのリンゴを貰って1つ食べました。 残りは何個ですか? ステップバイステップで考えてみましょう(※)前述したように GPT-4 モデルはこの程度の問題は正しい回答を返します。最近のモデルは指定しなくてもステップバイ ステップの回答を返すようですが例として使用しています
-
Generate Knowledge prompting : これはプロンプトに情報を含めることで、言語モデルの推論能力を向上させる手法です。知識が足りず上手く回答できない問題に対し、情報を追加して正しい回答を得られやすくします。
実際に以下のプロンプトを入力し、回答を確認します:
以下の配列の変数があり、1 から n までの数字が順番に格納されています。: array[n] 質問 : 以下の変数に格納されている数字はいくつですか? array[7]プログラムの配列のインデックスは 0 から開始されるため正しい回答は 8 ですが言語モデルは 7 と回答することがあります。このような場合には以下のプロンプトのように一文を追加することで正しい回答を求めることができます:
前提 : 配列のインデックスは 0 から開始されます。 以下の配列の変数があり、1 から n までの数字が順番に格納されています。: array[n] 質問 : 以下の変数に格納されている数字はいくつですか? array[7]
ここまで、代表的なプロンプト エンジニアリングの手法について確認しました。
プロンプト エンジニアリングの手法については多種多様なものがあり、視点やとらえ方も異なるものがあるので、さまざまな手法を試し目的にあったものを使用することが重要です。
プロンプト エンジニアリングの手法については以下のドキュメントをご参照ください。
- プロンプト エンジニアリングの技術
- Azure OpenAI Service を使用してプロンプト エンジニアリングを適用する
- Best practices for prompt engineering with the OpenAI API
- Prompt Engineering Guide
また、より実践的なプロンプト エンジニアリングを試されたいは、以下のリポジトリに豊富なサンプルが公開されていますのでぜひご活用ください。
アプリケーションからのプロンプトの利用
プロンプト エンジニアリングの手法は、プロンプトを記述するための技術であるためこの効果は利用者のスキルに左右されることになり、サービスやアプリケーションの提供者側からの制御は難しいものがあります。
また、アプリケーションにユーザーが言語モデルと対話するためのチャット UI を提供する場合、ユーザーがプロンプトを入力する際に、ユーザー敵対的なプロンプトを入力されるリスクもありますし、そもそもの問題として想定されたユースケース以外の利用をユーザーに許可するのか?、という問題もあります。
こういった状況を回避するアイディアのひとつとして、ユーザーにはアプリケーションのメニューやボタンを操作させ、アプリケーションの内部でプロンプトを生成する方法があります。
たとえば以下の GitHub リポジドリで公開されているアプリケーションは(※LLM ではなく SLM を使用していますが)
以下のようなメニューのイベント ハンドラー内でプロンプトを生成し、言語モデルに処理を行わせ結果を出力しています。
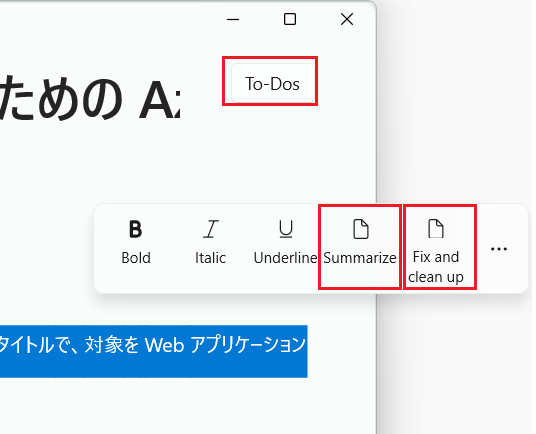
実際に処理を行っている部分は以下のようになります:
-
Summarize (要約)
return InferStreaming("", $"Summarize this text in three to five bullet points:\r {userText}", ct); -
Fix and clean (誤字脱字、文法チェック)
var systemMessage = "Your job is to fix spelling, and clean up the text from the user. Only respond with the updated text. Do not explain anything."; -
To-Dos (タスクリスト)
var system = "you are a helper that reads text and responds in json array format with any todo items in that text. If no todo items, respond with <no-todo>";
上記のようにユーザーの指定した文字列とアプリケーション内で用意したプロンプトを組み合わせることで、ユーザーに直接プロンプトを入力させなくても言語モデルを利用した様々な機能を提供することができます。
さらに具体的な例を挙げると、GitHub Copilot があります。GitHub Copilot のコード補完機能はチャット画面を持たず、ユーザーがコメントやコードを記述する際にプロンプトを生成し、言語モデルに処理を行わせ結果を出力しています。
このようにアプリケーションに言語モデルの機能を統合するのにプロンプトの入力画面 = チャット UI は必ずしも必要なものではありません。
また、生成 AI モデルを利用するとなると、これまでにない画期的な機能を提供しなければならないという謎の義務感に囚われるかもしれませんが、そんな必要はありません。
言語モデルを利用することで、これまで個別に機能を開発する必要があった以下のような機能がプロンプトを記述するだけで簡単に実現することができます:
- 要約
- 抽出
- 翻訳
- フォーマット変換
- オートコンプリート
- コード生成
- 画像認識 (マルチモーダルモデルを使用する場合)
- 文章チェック
- メールの文面作成
- 誤字脱字、文法チェック
- 文章へのレビュー
上記以外にも言語モデルに処理内容を説明することで、わざわざ新規にコードを記述しなくてもアイディア次第でアプリケーションにさまざまな機能を実装することができます。
また、言語モデルを利用するアプリケーションは、必ずしも人間が操作するアプリケーションである必要はありません。たとえば「旧来のシステムから定期的に送られてくる XML のデータを JSON に変換する」といった人間の操作が発生しない処理にも使用することもできます。
その際に言語モデルからの応答に自然言語が混じることなく、かつ任意の JSON スキーマを指定することができる Structured Outputs や JSON mode が用意されています。
まとめ
プロンプトを適切に利用することで、言語モデルの性能を向上させるだけでなく、利用の可能性も大きく広げることができます。